Text Generation Based on LSTM
This article is for LSTM Programming Exercise.
About LSTM
LSTM stands for Long Short-Term Memory, which is a type of recurrent neural network (RNN) that can learn long-term dependencies in sequential data. LSTM networks have a special structure that allows them to store and manipulate information over time, using gates that control the flow of information in and out of the network. LSTM networks are widely used for tasks such as natural language processing, speech recognition, machine translation, and more.
About text generation based on LSTM
LSTM for text generation is a technique that uses LSTM recurrent neural networks to generate text, character by character, based on a given input sequence. LSTM networks can learn the patterns and dependencies in sequential data, such as natural language, and then produce new and original sequences that are plausible for the given domain.
In this article, we built a LSTM model based on Pytorch, and we use Shakespeare’s opera as our training set. We firstly prepossessed words in the opera, built a dictionary to achieve transformation between words and index. We constructed training set, trained the model and generate prompt randomly for testing. As a result, our trained model can continuously generate text in Shakespeare’s literary style based on the input prompt.
Import libraries
import torch
import torch.utils.data as data
import numpy as np
import matplotlib.pyplot as plt
Set up parameters in training
epochs = 200
batch_size = 50
seq_length = 100 # Length of sequence in training set
learning_rate = 0.001
data_path = "../text.txt/text.txt"
# If cuda is available, then use GPU for training
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Data preprocessing
We use one of Shakesphere’s opera as training set. We can take a quick look of the read-in file text.txt:
Let’s read in this file, do preprocess we defined before and initialize our model. The data preprocessing work we do is mainly: reading the words in the file and converting the words into a list, then converting the list into a vector list for model training.
Create dictionary
Since neural network can only deal with digits instead of words, we firstly create a dictionary to achieve transformation between words and index.
# Dictionary used to transform word to index or index to word
class Dict():
def __init__(self):
self.word2idx = {}
self.idx2word = {}
self.index = 0
def __len__(self):
return len(self.word2idx)
# Add word if the word does not exist in the dictionary
def add_word(self, word):
if not word in self.word2idx:
self.word2idx[word] = self.index
self.idx2word[self.index] = word
self.index += 1
Read the file and convert it into vectors
Then we can read in the training file and convert it into vectors for training.
class Text2vector():
def __init__(self):
self.Dict = Dict()
self.idx = 0
self.nchars = 0
self.raw_text = []
# Open text file and save words into dictionary
# Read in file
def get_texts(self, data_path):
with open(data_path, 'r', encoding='utf-8') as f:
for line in f.readlines():
words = line.split()
for word in words:
self.raw_text.append(word)
self.Dict.add_word(word)
self.nchars += 1
# Generate training set
def divide_texts(self, seq_length):
datax = []
datay = []
# Convert file into lists
for i in range(0, 10000 - seq_length):
seq_in = self.raw_text[i: i+seq_length]
seq_out = self.raw_text[i + seq_length]
# Convert lists into vectors
for word in seq_in:
datax.append(self.Dict.word2idx[word])
datay.append(self.Dict.word2idx[seq_out])
n_patterns = len(datax)
y = torch.tensor(datay)
x = torch.tensor(datax, dtype=torch.float32).reshape(int(n_patterns/seq_length), seq_length, 1)
# Return data set for training
return x, y
Model construction
Let us construct our model! Our model consists of 4 layers, the first and second layer are LSTM layer, which is used for feature extraction in sequence of time. The third layer is drop-out layer, which is used to remove some data randomly to avoid overfitting. The fourth layer is linear layer that is responsible for generating vectors of the output text.
# Construct our model for training
class CharModel(torch.nn.Module):
def __init__(self, vocab_size):
super().__init__()
self.lstm = torch.nn.LSTM(input_size=1, hidden_size=1024, num_layers=2, batch_first=True)
self.dropout = torch.nn.Dropout(0.2)
self.linear = torch.nn.Linear(1024, vocab_size)
def forward(self, x):
x, _ = self.lstm(x)
x = x[:, -1, :] # Take only the last output
x = self.linear(self.dropout(x))
return x
Training
Before training, we also need to read in the text file and finish data pre-processing. What’s more, we also need to initialize our model, choose optimizer and loss function to use and put our model on GPU for acceleration.
#Read in file
text2vector = Text2vector()
text2vector.get_texts(data_path)
vocab_size = len(text2vector.Dict.idx2word)
# Initialize our model
model = CharModel(vocab_size)
model.to(device)
cost_function = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr = learning_rate)
After finishing all these work, we can get our training data set, seperate it into batches and start training our model. The training process may cost various of time according to the performance of your device. In this example, it costs me about 20 minutes to train the model on RTX 4060 Laptop GPU. You can also adjust training parameters and network structure we set before to achieve a better performance.
# Generate training set and separate it into batches
x, y = text2vector.divide_texts(seq_length)
loader = data.DataLoader(data.TensorDataset(x, y), shuffle=True, batch_size=batch_size)
loss = 0
loss_print = []
# Training
for epoch in range(0, epochs):
print("================ EPOCH: " + str(epoch) + "================")
for x_batch, y_batch in loader:
y_pred = model.forward(x_batch.to(device))
loss = cost_function(y_pred, y_batch.to(device))
model.zero_grad()
loss.backward()
# clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
loss_print.append(loss)
print("Loss: " + str(loss))
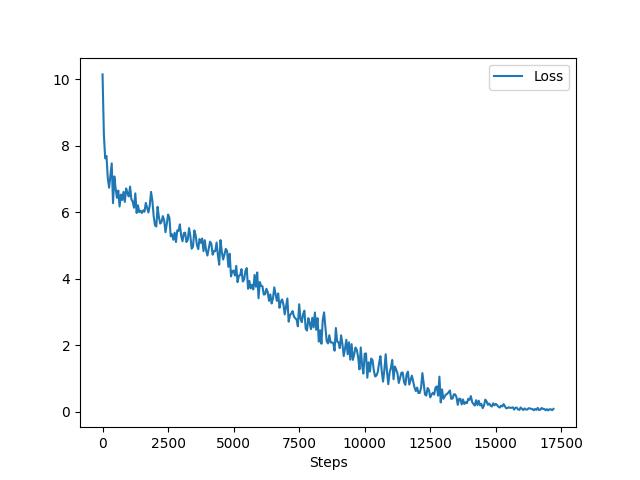
# Plot cost function
x = np.arange(1, len(loss_print) + 1, 50)
loss_print = [t.cpu().detach().numpy() for t in loss_print]
plt.figure()
# Plot one data point every 50 data points
plt.plot(x, loss_print[0:len(loss_print):50])
plt.legend(labels=["Loss"])
plt.xlabel("Steps")
plt.savefig('./Loss.jpg')
plt.show()
Now we can learn about our training results by either printed loss value in the console or plotted cost function below.
Model save and download
After training, we can save our model. Once needed, we can create a new model with the same structure to our old model and download saved parameters to the new model.
# Save model
torch.save(model, 'lstm.pt')
# Get model from saved path
new_state_dict = torch.load('lstm.pt')
new_model = CharModel(vocab_size)
new_model.load_state_dict(new_state_dict)
Testing
Nw we can generate prompt randomly from text file as input, to evaluate the performance of our model in text generation.
seq_length = 100
start = np.random.randint(0, 10000-seq_length)
prompt = text2vector.raw_text[start:start+seq_length]
pattern = [text2vector.Dict.word2idx[c] for c in prompt]
new_model.eval()
print('Prompt: "%s"' % prompt)
# Stop gradient descent
with torch.no_grad():
for i in range(1000):
x = np.reshape(pattern, (1, len(pattern), 1))
x = torch.tensor(x, dtype=torch.float32)
prediction = new_model(x)
index = int(prediction.argmax())
result = text2vector.Dict.idx2word[index]
print(result, end=' ')
pattern.append(index)
pattern = pattern[1:]
print()
print("Done.")
Now we can view the output of our generated model. In this example, our prompt for testing is:
”[‘Made’, ‘all’, ‘of’, ‘false-faced’, ‘soothing!’, ‘When’, ‘steel’, ‘grows’, ‘soft’, ‘as’, ‘the’, “parasite’s”, ‘silk,’, ‘Let’, ‘him’, ‘be’, ‘made’, ‘a’, ‘coverture’, ‘for’, ‘the’, ‘wars!’, ‘No’, ‘more,’, ‘I’, ‘say!’, ‘For’, ‘that’, ‘I’, ‘have’, ‘not’, “wash’d”, ‘My’, ‘nose’, ‘that’, ‘bled,’, ‘or’, “foil’d”, ‘some’, ‘debile’, ‘wretch.–’, ‘Which,’, ‘without’, ‘note,’, “here’s”, ‘many’, ‘else’, ‘have’, ‘done,–’, ‘You’, ‘shout’, ‘me’, ‘forth’, ‘In’, ‘acclamations’, ‘hyperbolical;’, ‘As’, ‘if’, ‘I’, ‘loved’, ‘my’, ‘little’, ‘should’, ‘be’, ‘dieted’, ‘In’, ‘praises’, ‘sauced’, ‘with’, ‘lies.’, ‘COMINIUS:’, ‘Too’, ‘modest’, ‘are’, ‘you;’, ‘More’, ‘cruel’, ‘to’, ‘your’, ‘good’, ‘report’, ‘than’, ‘grateful’, ‘To’, ‘us’, ‘that’, ‘give’, ‘you’, ‘truly:’, ‘by’, ‘your’, ‘patience,’, ‘If’, “‘gainst”, ‘yourself’, ‘you’, ‘be’, ‘incensed,’, “we’ll”, ‘put’]”
And the output of our model is:
“you, Like one that means his proper harm, in manacles, Then reason safely with you. Therefore, be it known, As to us, to all the world, that Caius Marcius Wears this war’s garland: in token of the which, My noble steed, known to the camp, I give him, With all his trim belonging; and from this time, For what he did before Corioli, call him, With all the applause and clamour of the host, CAIUS MARCIUS CORIOLANUS! Bear The addition nobly ever! All: Caius Marcius Coriolanus! CORIOLANUS: I will go wash; And when my face is fair, you shall perceive Whether I blush or no: howbeit, I thank you. I mean to stride your steed, and at all times To undercrest your good addition To the fairness of my power. COMINIUS: So, to our tent; Where, ere we do repose us, we will write To Rome of our success. You, Titus Lartius, Must to Corioli back: send us to Rome The best, with whom we may articulate, For their own good and ours. LARTIUS: I shall, my lord. CORIOLANUS: The gods begin to mock me. I, that now Refused most princely gifts, am bound to beg Of my lord general. COMINIUS: Take’t; ‘tis yours. What is’t? CORIOLANUS: I sometime lay here in Corioli At a poor man’s house; he used me kindly: He cried to me; I saw him prisoner; But then Aufidius was within my view, And wrath o’erwhelm’d my pity: I request you To give my poor host freedom. COMINIUS: O, well begg’d! Were he the butcher of my son, he should Be free as is the wind. Deliver him, Titus. LARTIUS: Marcius, his name? CORIOLANUS: By Jupiter! forgot. I am weary; yea, my memory is tired. Have we no wine here? COMINIUS: Go we to our tent: The blood upon your visage dries; ‘tis time It should be look’d to: come. AUFIDIUS: The town is ta’en! First Soldier: ‘Twill be deliver’d back on good condition. AUFIDIUS: Condition! I would I were a Roman; for I cannot, Being a Volsce, be that I am. Condition! What good condition can a treaty find I’ the part that is at mercy? Five times, Marcius, I have fought with thee: so often hast thou beat me, And wouldst do so, I think, should we encounter As often as we eat. By the elements, If e’er again I meet him beard to beard, He’s mine, or I am his: mine emulation Hath not that honour in’t it had; for where I thought to crush him in an equal force, True sword to sword, I’ll potch at him some way Or wrath or craft may get him. First Soldier: He’s the devil. AUFIDIUS: Bolder, though not so subtle.” …
Summary
From the results, we can see that our model is able to successfully generate text in Shakespeare’s literary style based on the input prompt. Although some of the words are not well generated, by increasing the complexity of our network, enlarging training set, adjusting training parameters and taking more in-depth training, the performance of our model can be further improved.