Machine learning Algorithm - Anomaly Detection and Recommender Systems
This article introduces the concept, formula derivation and suggestions of Anomaly Detection and Recommender Systems
Anomaly detection
Concept of anomaly detection
Anomaly detection is the process of identifying rare items, events, or observations that deviate significantly from the majority of the data and do not conform to a well-defined notion of normal behavior. These anomalies may be suspicious because they differ significantly from standard behaviors or patterns.
Just like in other machine learning problems, we have dataset X, now given a new example x_test, we want to know whether the new example is abnormal / anomalous.
Anomaly detection algorithm
- map the dataset to a Gaussian-like distribution. The Gaussian distribution probability function is as follows:
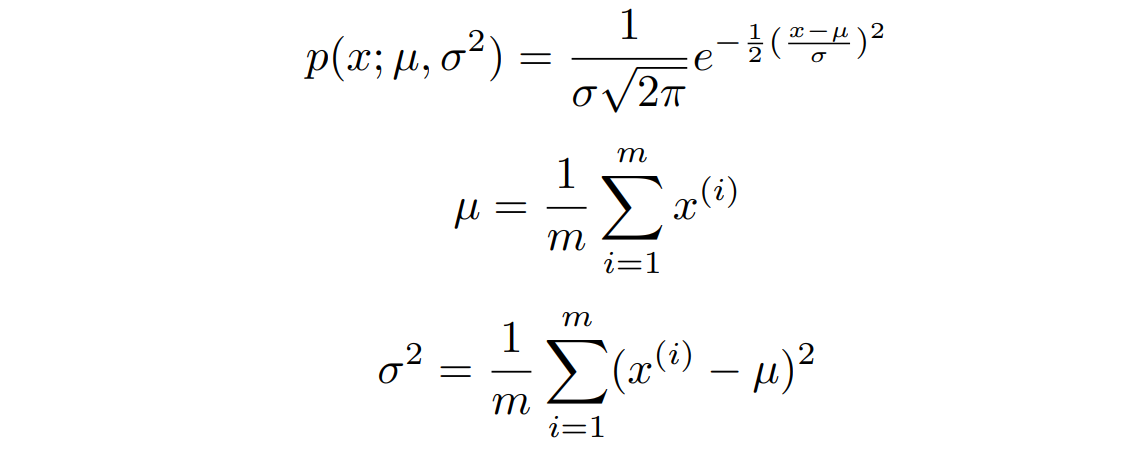
The mapping strategy you can try including:
- log(x)
- log(x + 1)
- log(x + c)
- x^(1/2)
- x^(1/3)
- …
- Calculate μj and σj^2.
- Given an example, calculate Probability p(x) as follows:
.png)
- If p(x) < ε ( ε is threshold we set), then let y = 1, we can draw the conclusion that x is anomaly. If p(x) >= ε, then let y = 0, we say x is normal.
Anomaly detection or supervised learning?
Use anomaly detection when
- We have a very small number of positive examples ( y = 1 )( 0 - 20 examples is common) and a large number of negative examples ( y = 0 ).
- We have so many different types of anomalies and it is hard for any other algorithms to learn from positive examples.
- Future anomalies may look nothing like the anamolous examples we have seen so far.
Use supervised learning when
- We have a large number of both positive and negative examples.
- We have enough positive examples for the algorithm to learn from positive examples what the anomalies look like.
- Future anomalies are similar to the anamolous examples in the training set.
Recommender systems
Concept of recommender systems
Recommender systems are algorithms that make recommendations to users about the best option to choose from a set of options. These systems are widely used in various applications and have become practically ubiquitous in our lives.
The main problem of recommender systems is recommender systems rely on user preferences and interactions to make recommendations. However, user input can be ambiguous or incomplete, making it challenging to accurately understand their preferences.
Recommender systems algorithm
We use movie recommendation as an example. In this example, we define that:
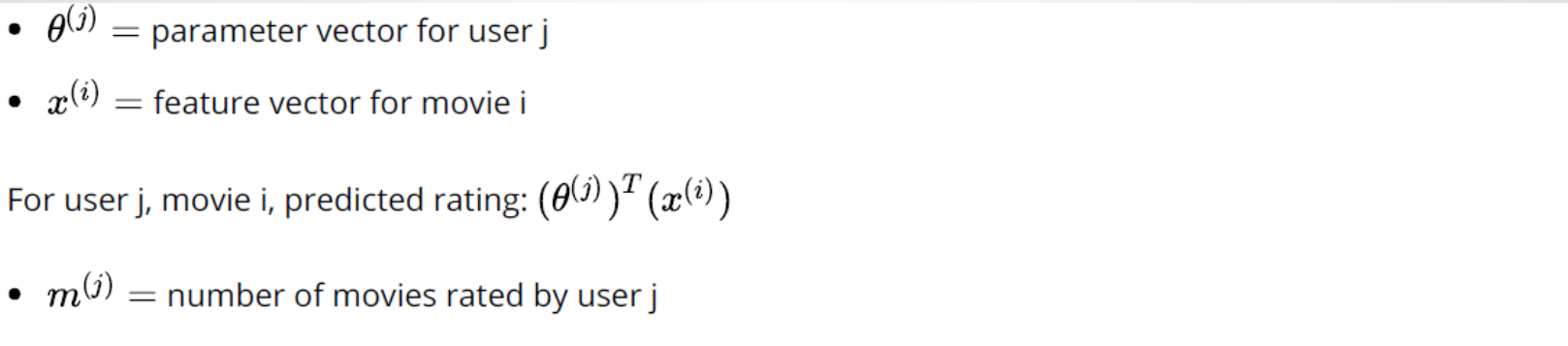
Content based recommendations

Collaborative filtering algorithm



Steps in collaborative filtering algorithm
